4.3 DataQuery
DataQuery를 이용하여 Object Storage에 저장된 로그 데이터를 Trino DB에 데이터를 저장하고 쿼리하는 방법을 가이드합니다.
4.3.1 Object Storage의 액세스 키, 비밀 키, 엔드포인트 정보
데이터 소스로 Object Storage를 연결하기 위해서는 Object Storage의 액세스 키, 비밀 키, 엔드포인트 정보가 필요합니다. 아래 'Object Storage의 정보를 가져오기’ 토글에서 상세 내용을 확인할 수 있습니다.
Object Storage 정보 가져오기
1. NHN Cloud 콘솔의 왼쪽 메뉴바에서 Storage > Object Storage로 이동합니다.
2. Object Storage에서 S3 API 자격 증명 버튼을 클릭합니다.
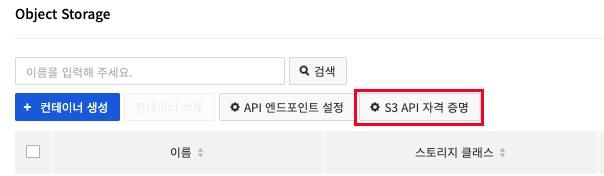
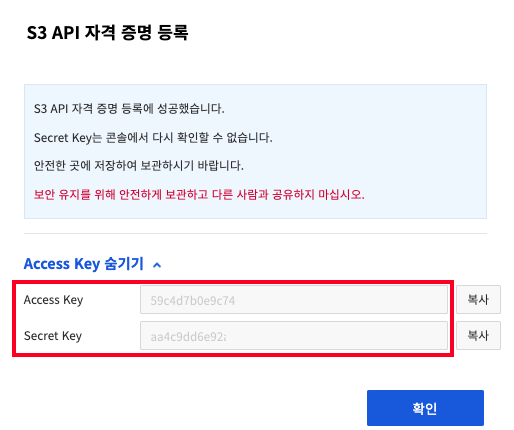
3. S3 API 자격 증명 등록 버튼을 클릭하여 Access Key와 Secret Key 정보를 확인합니다.
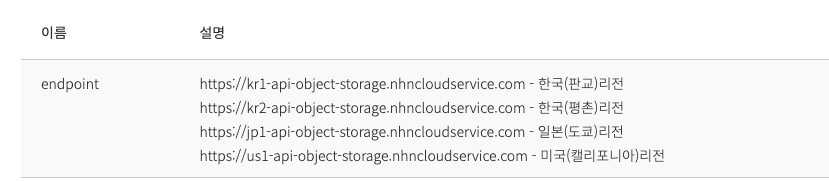
4. 엔드포인트(endpoint) 정보는 링크< 페이지에서 확인할 수 있습니다.
💡 DataQuery와 연동할 Object Storage가 서로 동일한 리전이 아닐 경우 네트워크 트래픽으로 인한 추가 요금이 발생할 수 있습니다.
4.3.2 데이터 소스 추가
DataQuery를 이용하기 위해서는 데이터 소스 추가가 필수로 필요 합니다. 데이터 소스에는 DataQuery에서 기본 테이블 정보나 관리 테이블 정보, 데이터를 저장하기 위해 사용하게 됩니다.
💡 데이터 소스의 Object Storage 컨테이너명은 dataquery-warehouse 이며 이름은 변경이 불가합니다. dataquery-warehouse 삭제 시 DataQuery 클러스터 시작이 불가합니다.
이 문서에서는 데이터 유형은 Object Storage 진행합니다.
DataQuery > 데이터 소스 > 데이터 소스 추가를 진행합니다.

4.3.3 클러스터 시작
데이터 소스를 반영하기 위한 클러스터를 시작합니다.
DataQuery > 쿼리 편집기 > 클러스터 켜키 버튼을 클릭합니다.
💡 클러스터 시작까지 3-4 분 정도의 시간이 소요됩니다.

데이터 소스를 dataquery-warehouse로 선택하고 스키마를 default로 선택합니다.
💡 스키마는 default만 사용 가능합니다.

4.3.4 테이블 생성
로그 데이터가 Object Storage에 쌓이는 형태에 맞춰 테이블과 컬럼을 생성합니다. 테이블 생성 과정에서 external_location을 사용하여 Object Storage의 경로를 지정하여 데이터 정보를 가져옵니다. 이를 통해 테이블은 Object Storage에 저장된 로그 데이터를 참조하게 됩니다.
partitioned_by를 사용하여 로그 데이터가 저장되는 형태에 맞춰 파티셔닝을 진행합니다. 파일이 쌓이는 방식에 따라 로그 데이터를 파티션화하여 저장하고 조회할 수 있게 됩니다. 이를 통해 월, 일, 시간 등의 파티션 컬럼을 기반으로 로그 데이터를 효율적으로 관리하고 검색할 수 있습니다.
이렇게 테이블과 컬럼을 Object Storage에 쌓인 로그 형태에 맞춰 생성하면, 로그 데이터를 효율적으로 관리하고 파티셔닝을 통해 원하는 조건에 맞는 로그를 빠르게 조회할 수 있습니다.
테이블 및 파티션 생성
# SQL
CREATE TABLE apache_log (
logType VARCHAR,
request VARCHAR,
agent VARCHAR,
auth VARCHAR,
ident VARCHAR,
logInfo VARCHAR,
body VARCHAR,
type VARCHAR,
logLevel VARCHAR,
clientip VARCHAR,
host VARCHAR,
logVersion VARCHAR,
timestamp VARCHAR,
logSource VARCHAR,
verb VARCHAR,
serviceName VARCHAR,
sendTime VARCHAR,
logTime VARCHAR,
referrer VARCHAR,
environment VARCHAR,
response VARCHAR,
bytes VARCHAR,
httpversion VARCHAR,
projectName VARCHAR,
projectVersion VARCHAR,
month INT,
day INT,
hour INT
)
WITH (
format = 'json',
external_location = 's3a://apache-access/2023/',
partitioned_by = ARRAY['month', 'day', 'hour']
);

테이블이 정상적으로 생성이 되었는지 확인합니다.

아직은 테이블은 생성은 되었지만 로그들은 쌓이지 않은 것을 확인할 수 있습니다.
sync_partition_metadata 명령어를 이용하여 테이블의 파티션 메타데이터를 동기화합니다.
이 과정을 통해 Object Storage의 폴더 구조에 맞춰 파티셔닝을 진행하고 데이터를 sync 하게 됩니다.
아래 ‘테이블 파티션 동기화’ 토글에서 쿼리문을 복사하여 DataQuery 쿼리에 붙여넣고 실행합니다.
# SQL
CALL system.sync_partition_metadata('default', 'apache_log', 'FULL');
아래 테이블 조회 쿼리문으로 DataQuery를 통해 Object Storage에 보관된 데이터가 조회되는지 확인합니다.
# SQL
select * from apache_log아래와 유사한 결과가 출력된다면 정상적으로 설정이 완료되었습니다.

5. 결론
NHN Cloud Native 서비스를 활용하여 Log pipeline을 설정하였습니다. Log pipeline을 통해 여러 서버에서 발생하는 로그를 한 곳에서 효율적으로 수집하고 조회할 수 있었습니다.
간단한 로그들의 설정은 비교적 쉬웠으나, 많은 커스텀 로그가 존재하는 경우에는 설정에 많은 시간이 소요될 것으로 예상됩니다. 또한, nhn cloud 공식 가이드 문서가 미흡하여 로깅 파이프라인에 대한 사전 지식이 없다면 설정하는 데에 시간이 더 소요될 수 있습니다. 오픈소스의 공식 문서를 활용하는 것을 권장합니다.
'NHN Cloud' 카테고리의 다른 글
| [NHN Cloud] Site-to-Site VPN 설정 (0) | 2023.11.09 |
|---|---|
| NHN Cloud 에서 Log Pipeline 만들기 (1) (1) | 2023.10.19 |
| [NHN Cloud] ALB 대체 방안 (0) | 2023.10.18 |
| [NHN Cloud] NKS 구성 (1) | 2023.10.09 |
| NHN Cloud에서 서비스 모니터링을 이용해 서비스 상태 파악하기 (0) | 2023.09.30 |



